Using GPT-Vision
Many OpenAI models support a Vision feature that allows you to upload images and reference them in your prompts. To create tasks using this feature, utilize the Prompt with Files node.
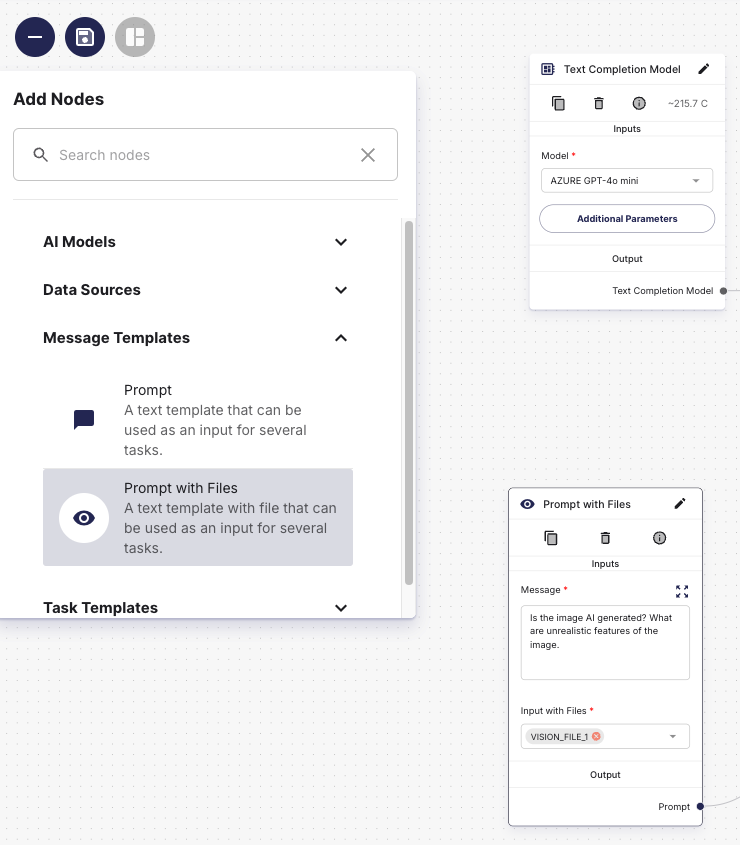
Setting Up the Input Template
Before using the Prompt with Files node, define an Input Template of the File URL input type. This ensures the template will be available when configuring prompts with files.
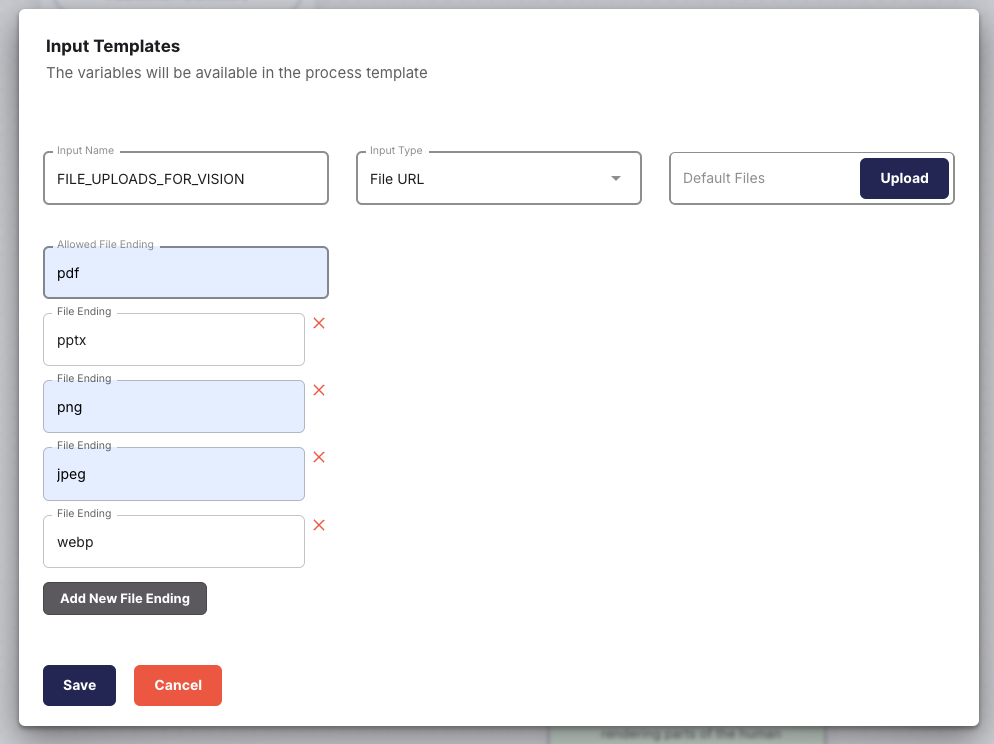
Allowed File Types
When using GPT-Vision, the following file types are supported:
- webp
- png
- jpeg
- pdf – Converted into one image per page:
- The quality may be lower than the original.
- Large or unusual dimensions can be problematic.
- If you need to preserve very high quality, submit pages individually.
- pptx – Converted into one image per slide (quality may be reduced).
Note: Make sure the file extension matches the actual file type.
Image Submission Limits
You can submit up to 10 images in a single request. Tests suggest that including more images in one request may reduce output quality.
Models Supporting Vision
The following models support vision:
- azure gpt-4o-mini
- gpt-4o-mini
- azure-4-o
- gpt-4-turbo-with-vision (only describes the first picture)
- gpt-4-o
Important: If you select a model that does not support vision, it may hallucinate and describe a random image you did not provide. Some models may explicitly indicate they cannot process images.