Placeholder Patterns
There are different kinds of placeholders, which can be used to supply user-defined content, reference previous tasks or ingest data for retrieval augmented generation (RAG).
Placeholders are always marked using curly brackets {} in the prompt. Depending on the type (resolving Input Templates or Chaining Tasks), a predefined syntax must be followed. Each type of placeholder is only getting resolved once per occurrence to avoid inflating the prompt infinetely due to recursion.
The example below shows a placeholder for an Input Template. The placeholder {FILE_CONTENT} will be replaced with the parsed content of the uploaded file at runtime. In case the file contains the sequence for another {PLACEHOLDER_FOR_INPUT_TEMPLATE}, that placeholder will not get resolved.
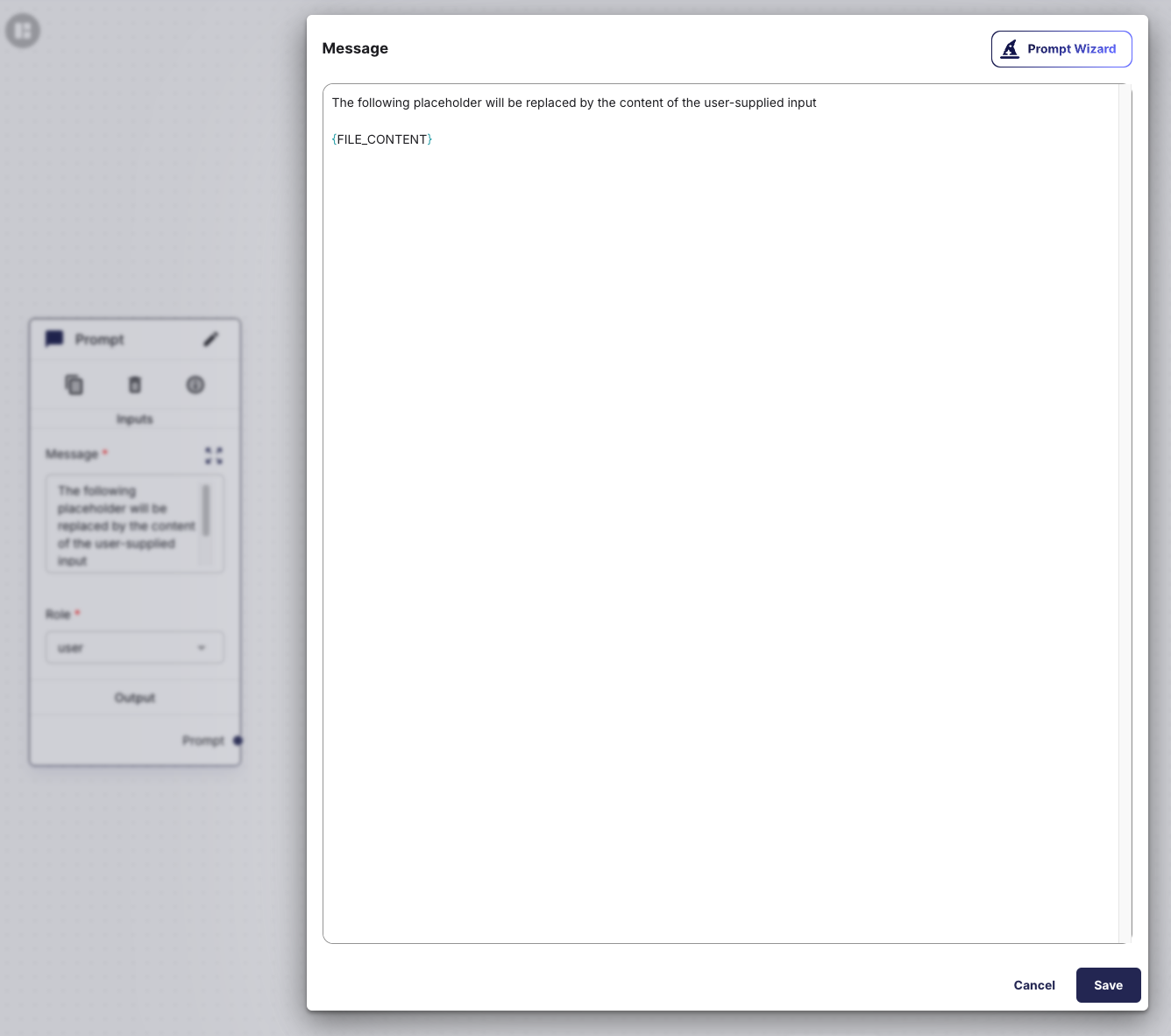
The following subsection describe the syntax for the different kinds of placeholders and their behaviour.
Input Templates
The placeholders for the Input Templates must always be in {SNAKE_CASE}. The process will not throw errors or warnings in case your prompt contains placeholders with typos, that can not be matched with any Input Template. There will also be no warnings or errors, in case you define an Input Template, but it is never used in a prompt.
Chaining Tasks
When you chain tasks by drawing an edge between them, the placeholder {task_x.output_0} is used internally. Whereas the xis used to denote the logical position of the task inside the process template (starting at 0). You can check the logical position of the task by clicking on the i-icon on the respective node. You do not have to dive deeper into those placeholders, in case you are just chaining simple text completion tasks. We are taking care of the placeholders for you.
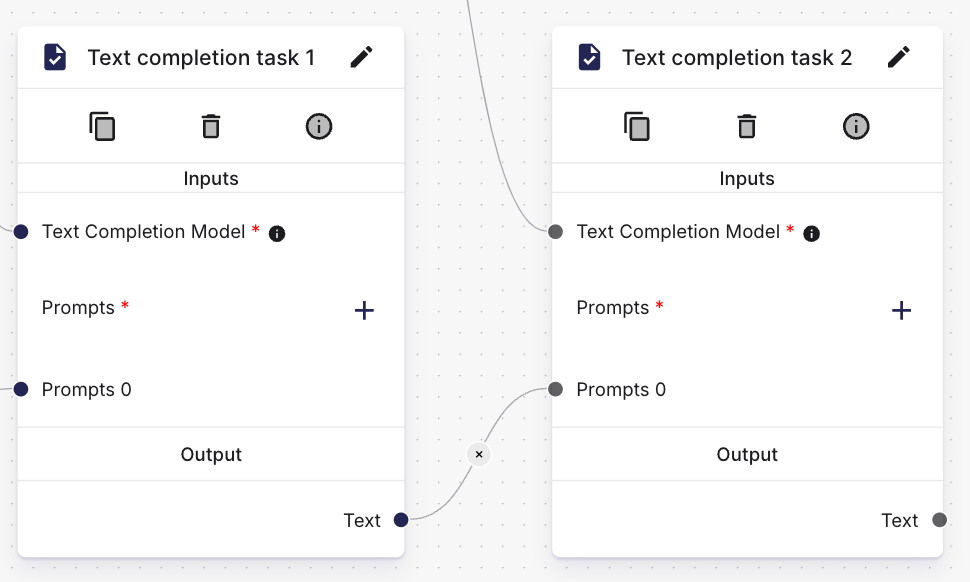
Whenever you are working with tasks that generate multiple outputs (e.g. by setting the amounts of images to be generated or top_k for vector store retrieval tasks to >1), or you want to access structured metadata from certain tasks (metadata from retrieval tasks), you can use the following placeholder patterns manually to finish the job:
{task_x.output_y}- You can use a different value for y to reference different outputs. For example, you can use{task_1.output_2}to reference the third best result (we start counting at 0) from a vector store retrieval task.{task_x.output_all}- All outputs from the task at positionxwill be concatenated using new-line characters.
Vector Store Retrieval
The example below uses an edge between the Vector Store Retrieval Task and the Text Completion Task. This will use the chunk text from the top result. Though, the other results are not incorporated by just using an edge.
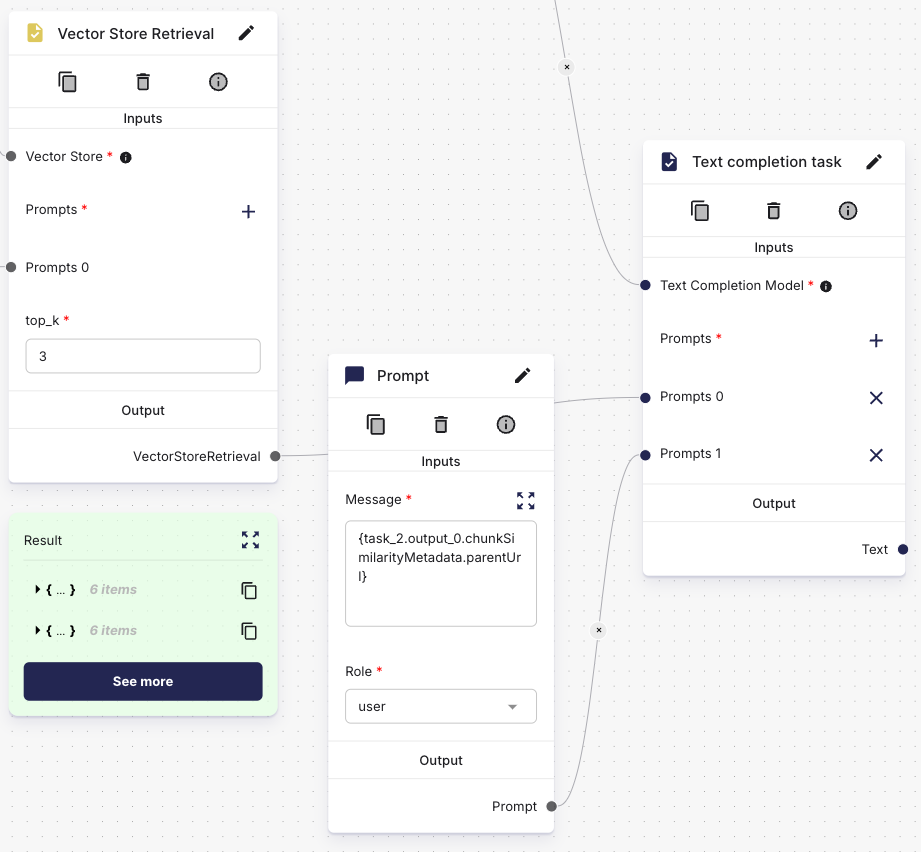
More patterns are available to reference outputs from Vector Store Retrieval Tasks:
{task_x.output_y.chunkSimilarityMetadata}- This uses all metadata fields and wraps them in a single JSON element like below:
{
"chunkSimilarityMetadata": // - always used to wrap the metadata
{
"score": 0.76, // - always present, marks the similarity score
"chunkId": "chunkId_xyz_2", // - always present, contains the id of the chunk
"chunkText": "<chunk text>", // - (almost) always present, contains the chunk text behind the embedding
"parenUrl": "http://example.com/some-file", // - can be used to fetch and parse the file inside the process, can get an updated SAS-token if hosted by entaingine
"file-url": "http://example.com/some-file", // - can be used to fetch and parse the file inside the process, can get an updated SAS-token if hosted by entaingine
"another-url-key": "http://example.com/some-file" // - can NOT be used to fetch and parse the file inside the process, the maintainer of the vectorStore is responsible to keep the URL up to date and reachable
}
}
{task_x.output_y.chunkSimilarityMetadata.<someMetadatakey>}- This just returns the data at a specifc metadata key without any added formatting.{task_x.output_y.chunkSimilarityMetadata.parentUrl}- This is a special case, where the entire document behind the URL is getting fetched and parsed. This also works for the keyfile_url.
{task_x.output_all.chunkSimilarityMetadata}- This wraps chunkSimilarityMetada JSON-objects from all outputs into a JSON-array like below:
[
{
"chunkSimilarityMetadata": {...}
},
{
"chunkSimilarityMetadata": {...}
}
]
{task_x.output_all.chunkSimilarityMetadata.<someMetadatakey>}- This returns the data at a specifc metadata key for all outputs concatenated with new-line characters\n. Be careful, asfile_urlandparentUrlmetadata keys will be replaced with the full content of the files. This could easily fill out the entire context window in some cases!