Automatic Prompt Engineer (APE)
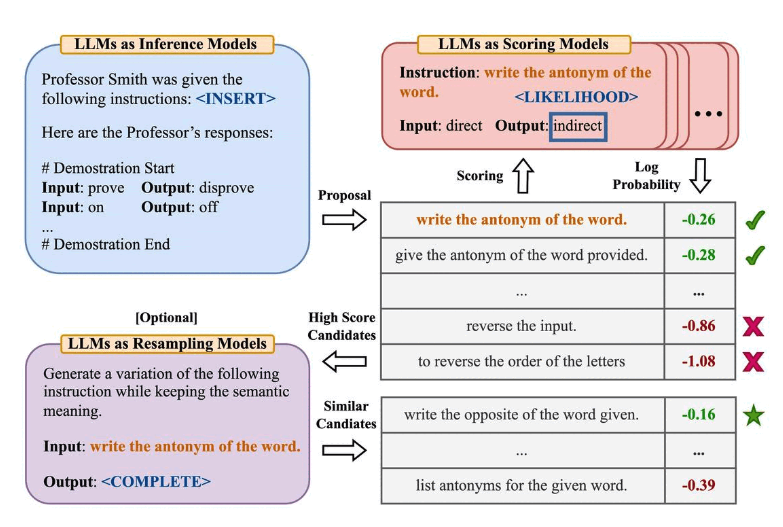
Automatic Prompt Engineer (APE) is a technique that leverages language models themselves to automatically generate, test, and refine prompts for specific tasks. Instead of manually crafting prompts through trial and error, APE uses systematic approaches to discover high-performing prompt formulations, often surpassing human-designed prompts.
Introduced by Zhou et al. (2022), APE treats prompt generation as a natural language synthesis problem, where the model is asked to generate instructions that would lead to desired outputs given specific inputs.
How APE Works
The APE process typically involves several key steps:
- Prompt Generation: The model generates multiple candidate prompts based on input-output examples
- Evaluation: Each candidate prompt is tested on a validation set
- Selection: The best-performing prompts are identified based on accuracy or other metrics
- Iteration: The process can be repeated to further refine prompts
Use Cases
APE is particularly valuable when:
- Manual prompt engineering is time-consuming or requires domain expertise
- You need to optimize prompts for specific metrics (accuracy, consistency, style)
- Working with new tasks where effective prompt patterns aren't well-established
- Scaling prompt optimization across multiple similar tasks
Implementation Patterns
Basic APE Pattern
Task: Generate a prompt that will help classify customer reviews as positive or negative.
Given these examples:
Input: "This product exceeded my expectations!"
Output: Positive
Input: "Waste of money, poor quality"
Output: Negative
Generate 5 different prompts that would work well for this classification task.
Iterative Refinement
Here are 3 prompts for sentiment analysis:
1. "Classify this review as positive or negative:"
2. "Determine the sentiment (positive/negative) of this customer feedback:"
3. "Is this review expressing a positive or negative opinion?"
Based on testing, prompt #2 performed best. Generate 3 improved variations of prompt #2.
Meta-Prompt for APE
You are an expert prompt engineer. Your task is to create effective prompts for [SPECIFIC TASK].
Requirements:
- The prompt should be clear and unambiguous
- It should work well across diverse inputs
- Include any necessary context or formatting instructions
Generate 5 candidate prompts, then explain why each might be effective.
Advanced Techniques
Chain-of-Thought APE
APE can be combined with chain-of-thought prompting to generate prompts that encourage step-by-step reasoning:
Generate a prompt that asks the model to solve math word problems by thinking step by step. The prompt should encourage the model to:
1. Identify what information is given
2. Determine what needs to be found
3. Set up the calculation
4. Solve and verify the answer
Multi-Objective APE
When optimizing for multiple criteria simultaneously:
Create prompts for summarizing research papers that optimize for:
- Accuracy (capturing key findings)
- Brevity (under 100 words)
- Accessibility (understandable to non-experts)
Generate 3 prompts that balance these objectives.
Evaluation and Testing
Effective APE requires systematic evaluation:
Quantitative Metrics
- Accuracy: Percentage of correct outputs on test cases
- Consistency: Variance in outputs across multiple runs
- Efficiency: Token usage and response time
Qualitative Assessment
- Clarity: How well the prompt communicates the task
- Robustness: Performance across edge cases and diverse inputs
- Generalization: Effectiveness on unseen examples
Implementation Example
Here's a complete APE workflow for creating a code documentation prompt:
Step 1: Define the task
Task: Generate clear, concise documentation for Python functions
Step 2: Provide examples
Input: def calculate_area(radius): return 3.14159 * radius ** 2
Output: Calculates the area of a circle given its radius. Returns the area as a float.
Step 3: Generate candidate prompts
1. "Write documentation for this Python function:"
2. "Create a brief description of what this function does:"
3. "Generate a docstring explaining this function's purpose and return value:"
4. "Describe this function in one clear sentence:"
5. "Document this function including its purpose and output:"
Step 4: Test and evaluate
[Test each prompt on validation set]
Step 5: Select and refine best performer
Best: Prompt #3
Refined: "Generate a concise docstring for this Python function, explaining its purpose, parameters, and return value:"
Best Practices
For Prompt Generation
- Provide diverse, high-quality examples
- Be specific about desired output format and style
- Include edge cases in your evaluation set
- Consider the target model's capabilities and limitations
For Evaluation
- Use held-out test sets to avoid overfitting
- Evaluate on multiple metrics relevant to your use case
- Test prompts with different model temperatures and sampling methods
- Consider human evaluation for subjective tasks
For Iteration
- Start with simple prompts and gradually increase complexity
- Document what works and what doesn't for future reference
- Consider prompt ensembles for critical applications
- Regular re-evaluation as models and tasks evolve
Limitations and Considerations
Computational Cost: APE requires multiple model calls for generation and evaluation, which can be expensive.
Evaluation Challenges: Defining good evaluation metrics can be difficult for subjective or creative tasks.
Overfitting Risk: Prompts optimized on small datasets may not generalize well.
Context Dependence: Optimal prompts may vary significantly across different models or domains.
Human Oversight: Automated prompt generation should be combined with human review, especially for sensitive applications.
Integration with Other Techniques
APE can be combined with other prompting techniques:
- Few-shot learning: Generate prompts that include optimal examples
- Chain-of-thought: Create prompts that encourage reasoning
- Self-consistency: Develop prompts optimized for multiple sampling
References
- Zhou, Y., et al. (2022). Large Language Models Are Human-Level Prompt Engineers. arXiv preprint arXiv:2211.01910
- Reynolds, L., & McDonell, K. (2021). Prompt Programming for Large Language Models: Beyond the Few-Shot Paradigm. Extended Abstracts of CHI 2021
- Wei, J., et al. (2022). Chain-of-Thought Prompting Elicits Reasoning in Large Language Models. NeurIPS 2022